- All judicial decisions need to be anonymised before being made public. Currently, the process of removing personal data is entirely manual and requires a lot of the working time of court staff, including of judges, which makes it significantly time-consuming and costly;
- The difficulties in performing this task manually make it impossible to publish all court decisions.
Automated anonymization of court decisions (ongoing)
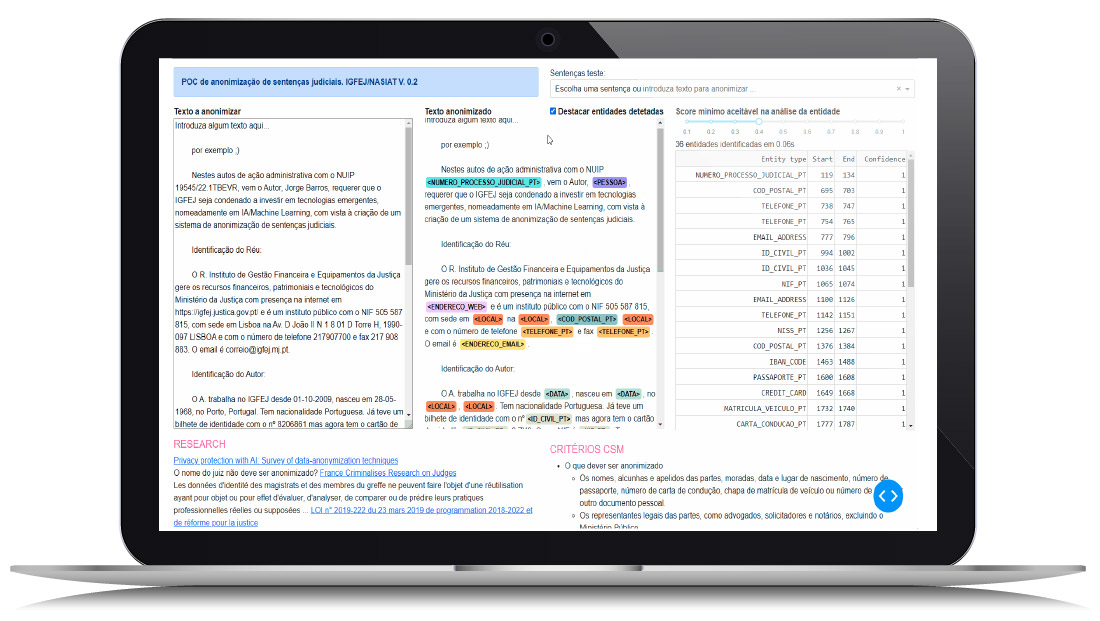
- Use of tools based on machine learning and artificial intelligence to detect and anonymise personal data in judicial decisions, complying with the latest publication standards and following open data policies, which facilitate their processing and analysis by the legal community, but also by the scientific and academic community.
- Pilot project to anonymise the decisions of the Administrative and Fiscal Courts.
- Availability of advanced search mechanisms that will allow judges to have faster access to information on similar cases, which can be used as jurisprudence or to identify the diplomas that supported the decisions, facilitating a greater sharing and standardisation of court decisions;
- The use of artificial intelligence techniques will also provide summaries to assist judges in decision making and jurisprudential analysis, thereby helping to speed up the time taken to analyse cases.
- Reduces the allocation of court staff to this task, allowing them to dedicate more time to higher value-added tasks.
- Increases transparency by facilitating the publication of all court decisions and thus enabling greater access by various stakeholders, academia, and civil society.
- It offers improved tools to support the decision making of judges and contributes to the consistency of the jurisprudence.
- Allows the study of the interpretation and application of law, as well as of the impact of legislative choices of justice policies.